내 웹페이지가 로딩될때 일어나는 일 (1)
2023년 8월 15일
드디어 개발을 끝냈다.
만약 제가 정말 단순한 웹페이지를 개발했다고 가정해보겠습니다.
<!DOCTYPE html>
<html lang="ko">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>버튼 페이지</title>
<style>
#number {
color: #333;
size: 24px;
}
#button-box {
display: flex;
}
.button {
padding: 2px;
border-radius: 10px;
background-color: lightblue;
}
</style>
</head>
<body>
<div id="number">1</div>
<div id="button-box">
<button class="button" id="add">증가</button>
<button class="button" id="sub">감소</button>
</div>
</body>
<script>
const addButton = document.getElementById('add')
const subButton = document.getElementById('sub')
const numberDiv = document.getElementById('number')
const calculateNumber = (type, number) => {
if (type === 'add') numberDiv.innerHTML = Number(numberDiv.innerHTML) + 1
if (type === 'sub') numberDiv.innerHTML = Number(numberDiv.innerHTML) - 1
}
addButton.addEventListener('click', () =>
calculateNumber('add', numberDiv.innerHTML)
)
subButton.addEventListener('click', () =>
calculateNumber('sub', numberDiv.innerHTML)
)
</script>
</html>정말 간단하게 버튼을 누르면 숫자가 증가하고, 감소하는 카운트 페이지 입니다. html과 css 그리고 조금의 자바스크립트 코드로 이루어진 아주 단촐한 페이지입니다.
그렇다면 이 페이지를 열었을때 일어나는 일에 대하여 모두 알고계신가요?
이 html파일을 열었을때 일어나는 일에 대하여 간단하게 정리해보겠습니다.
내가만든 페이지에 접속하기
우선, 제가 해당 페이지를 개발후 내 웹사이트에 등록을 했다고 가정합니다. 그렇다면 당연히 먼저 사이트에 접속을 해야할 것입니다.
DNS서버에서 내 웹사이트 IP 가져오기
저희가 사용하는 브라우저를 켠 후 주소창에 제 웹사이트 주소를 입력합니다. jeongyeon.com이라는 웹사이트로 접속하겠습니다.
그러면 브라우저는 jeongyeon.com라는 도메인과 대응되는 IP주소를 DNS서버에서 찾습니다.
-
DNS 서버란?
DNS Server는 IP 주소와 Domain 이름을 기억하는 기능과 Client가 Domain 이름을 물어보면 IP를 알려주는 기능을 갖고 있습니다.
일반적으로 브라우저는 똑똑하기 때문에 이러한 요청이 있었다면, 캐싱된 주소를 가지고 있습니다. 이를 DNS캐시라고 합니다.
# 로컬 DNS 캐시를 확인하는 방법
sudo dscacheutil -q host -a name naver.com
name: naver.com
ip_address: 223.130.195.200
ip_address: 223.130.200.104
ip_address: 223.130.200.107
ip_address: 223.130.195.95브라우저는 다음과 같은 4단계의 DNS캐시를 확인합니다.
- 브라우저 캐시 : 사용자가 방문했던 DNS기록을 보관합니다.
- OS 캐시 : OS가 DNS기록을 보관합니다.
- 라우터 캐시 : 자체 DNS기록을 유지관리하는 라우터캐시입니다.
- ISP 캐시 : DNS서버를 가지고 있기에, 해당 서버의 DNS기록을 조회할수 있습니다.
다만 이러한 DNS캐시들도 오래된것들은 이전정보를 가지고 있을수 있으므로 지속적으로 업데이트 해줍니다.
만일 로컬 DNS 서버에 해당 주소를 찾지 못할경우 루트 DNS 서버에 문의합니다.
루트 DNS 서버는 최상위 도메인이 .com 인것을 확인 후 “.com”이 등록된 네임 서버의 ip 주소를 전달해줍니다.
이제 다시 로컬 DNS 서버는 .com DNS 서버에 주소를 물어보면, .com DNS 서버는 해당주소를 모르므로 jeongyeon.com도메인을 관리하는 DNS서버의 ip 주소를 알려줍니다.
마지막으로 해당 DNS 서버에서 jeongyeon.com의 주소를 알려줌으로 우리는 jeongyeon.com의 ip 주소를 얻게되는것입니다.
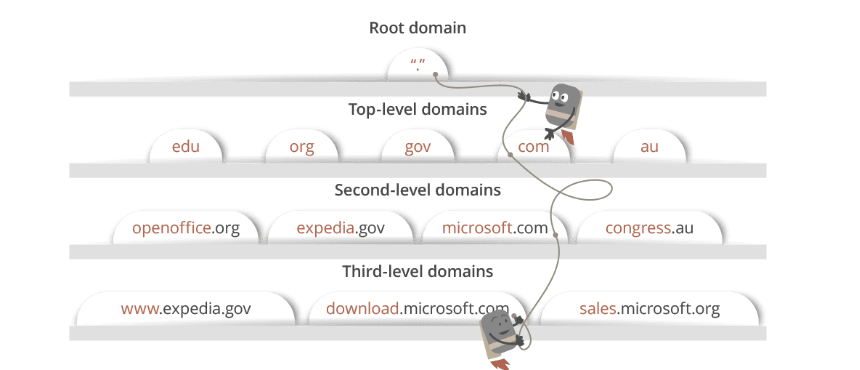
그림과 함께 정리를 해보면 다음과 같은 순서로 ip 주소를 받아올수 있습니다.
캐싱된 로컬 DNS 서버 -> 루트 DNS 서버 -> 최상위 DNS 서버 -> 세컨드 레벨 DNS 서버
# 간단한 dns 계층구조
blog.jeongyeon.com.
sub / second / top / root이러한 DNS 서버를 이동하며 ip주소를 찾는 과정을 Recursive serch 라고합니다.
참고로 도메인 이름구조에서 최상위의 위치한곳은 ICANN이라는 비영리 단체입니다. 이 단체는 전세계에 있는 IP 주소를 관리함과 동시에 Root Name Server의 관리자 역할을 하고 있습니다.
Root Name Server 밑에는 Registry라는 등록소가 존재하는데, 얘네는 Top-level domain(.com)을 관리합니다. 그 다음으로는 Registrar라고 하는 등록 대행자가 있는데, 등록 대행자는 등록자가 등록소에 등록하는 것을 등록해주는 대행역할을 해줍니다.
찾은 ip 주소와 연결
이제 찾은 주소와 브라어주는 TCP 연결을 합니다.
TCP는 3-way-handshake 과정을 통해서 연결 및 데이터를 수신받습니다.
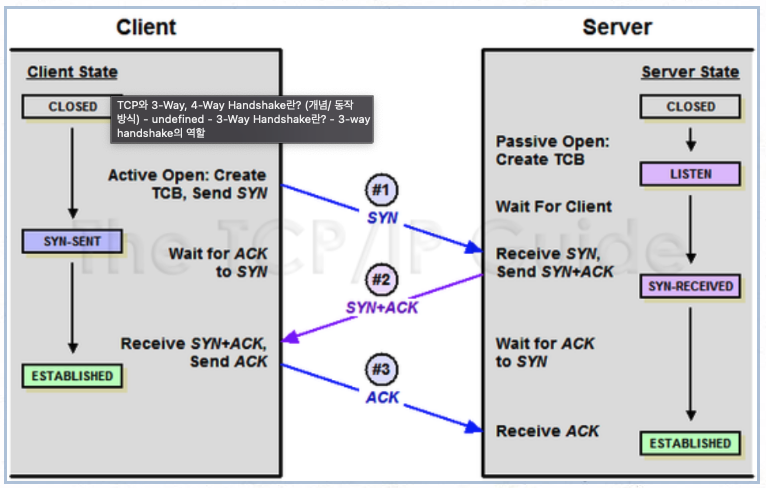
- 클라이언트에서 서버에 접속요청을 하는 SYN 패킷을 전송합니다.
- 서버는 접속요청을 받고 SYN_ACK flag 패킷을 전송합니다.
- 클라이언트는 ACK 패킷을 전송하고 연결이 성립됩니다.
다음은 연결 종료를 위한 4-way-handshake 과정입니다.
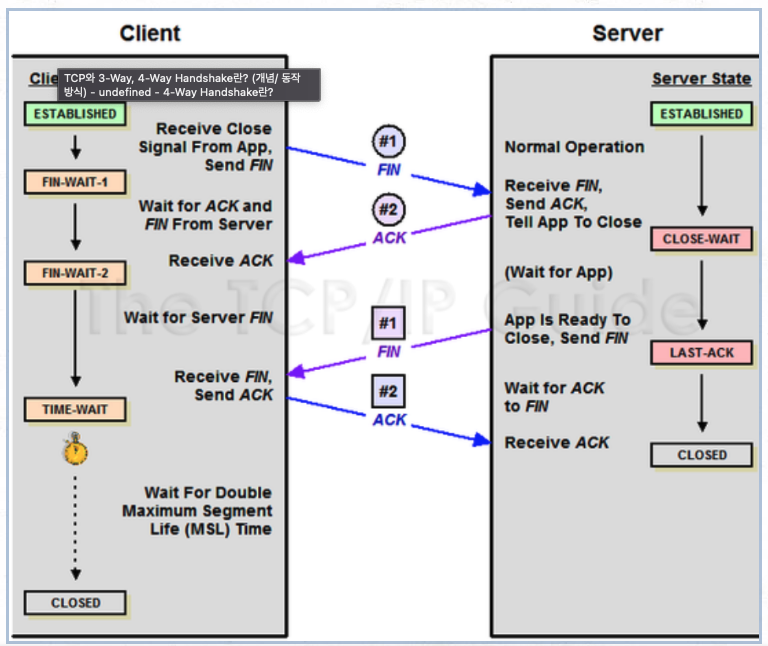
- 클라이언트가 연결을 종료하겠다는 FIN 패킷을 전송합니다.
- 서버는 ACK 패킷을 전송하고 자신의 통신이 끝날때까지 대기합니다.
- 서버의 통신이 종료되면 클라이언트에게 FIN 패킷을 전송합니다.
- 서버는 마지막으로 확인의 ACK 패킷을 전송합니다.
- 클라이언트는 FIN을 수신하더라도 잉여 패킷이 올수있어 TIME_WAIT과정을 마지막으로 거치게 됩니다.
3-way-handshake 통해 ip주소와 연결된 브라우저는 웹 서버에 http 요청을 진행합니다.
html 파일을 받아보자
이렇게 TCP 연결 이후 http 통신을 통해 웹서버에 html 파일을 요청합니다. 물론 html 이나 css같은 스태틱한 파일은 웹 서버에서 줄수있지만, 나머지 동적인 처리를 위해 웹 어플리케이션 서버도 이용합니다.
만약 처리될 데이터가 있다면 엡 어플리케이션 서버에서 데이터를 웹서버로 전송하고, 웹 서버는 브라우저에게 html 파일을 전달합니다.
이런 과정을 통해 우리는 jeongyeon.com에 접속해 html 파일을 받아올수 있습니다.
html을 이제 어떻게할까요?
이제 html 파일을 받았으니 우리는 그안에 html태그로 버튼을 만들고 css로 스타일을 입힌뒤에 js로 동작을 추가해줄것입니다. 그리고 브라우저에 사용자가 볼수있도록 화면에 보여줄것입니다.
우리는 이러한 일련의 과정을 렌더링이라고 합니다.
이러한 렌더링과정을 위해 브라우저 내에는 렌더링 엔진을 내장하고 있으며, 크롬의 경우 blink 라는 내장 렌더링 엔진을 가지고 있습니다.
렌더링 엔진은 통신으로부터 요청한 문서의 내용을 얻는 것으로 시작하는데 문서의 내용은 보통 8KB 단위로 전송됩니다.
우선적으로 html dom 트리를 생성합니다.
해당 트리를 만들기 위해서는 다음과 같은 과정을 진행합니다.
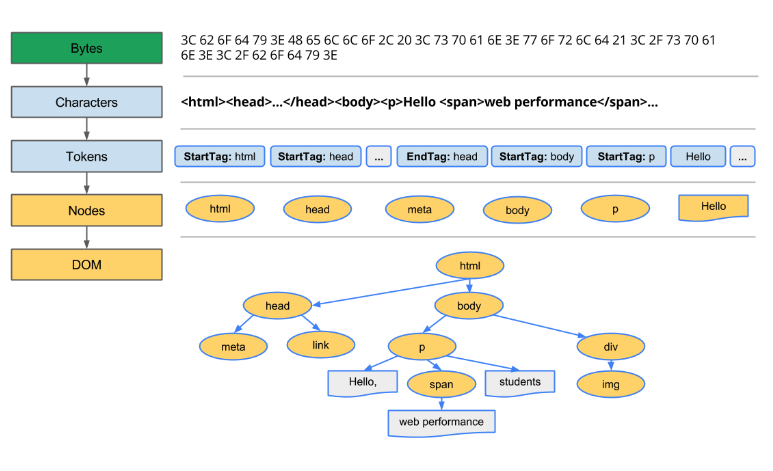
-
변환
- 브라우저가 HTML의 원시 바이트를 읽어와서, HTML에 정의된 인코딩(예: UTF-8)에 따라 개별 문자로 변환합니다.
-
토큰화
- 브라우저가 문자열을 W3C 표준에 지정된 고유 토큰으로 변환합니다.
- 토큰화 과정은 ”<“을 만나면 태그열림으로 인식하고, ”>“을 만날때까지 나머지느 알파벳은 태그이름으로 인식합니다. (<는 3C / >는 3E)
- 이 과정을 모든 html을 읽을때까지 반복합니다.
-
렉싱
- 방출된 토큰은 해당 속성 및 규칙을 정의하는 “객체”로 변환됩니다.
-
DOM 생성
- HTML 마크업에 정의된 여러 태그 간의 관계를 해석해서 트리 구조로 연결이 됩니다.
- 해당 트리 데이터 구조는 원래 마크업에서 정의된 상위-하위 관계도 포함이 됩니다.
while (true) { if (should_process_preloading) FlushPendingPreloads(); const auto next_token_status = CanTakeNextToken(time_executing_script); if (next_token_status == kNoTokens) { // No tokens left to process in this pump, so break break; } if (next_token_status == kHaveTokensAfterScript && task_runner_state_->HaveExitedHeader()) { // Just executed a parser-blocking script in the body. We'd probably like // to yield at some point soon, especially if we're in "extended budget" // mode. So reduce the budget back to at most the default. budget = std::min(budget, task_runner_state_->GetDefaultBudget()); if (TimedParserBudgetEnabled()) { timed_budget = std::min(timed_budget, chunk_parsing_timer.Elapsed() + GetDefaultTimedBudget()); } } HTMLToken* token; { RUNTIME_CALL_TIMER_SCOPE( V8PerIsolateData::MainThreadIsolate(), RuntimeCallStats::CounterId::kHTMLTokenizerNextToken); token = tokenizer_.NextToken(input_.Current()); // input이 입력데이터 객체입니다. if (!token) break; budget--; tokens_parsed++; } AtomicHTMLToken atomic_html_token(*token); // Clear the HTMLToken in case ConstructTree() synchronously re-enters the // parser. This has to happen after creating AtomicHTMLToken as it needs // state in the HTMLToken. tokenizer_.ClearToken(); ConstructTreeFromToken(atomic_html_token); // 만든 토큰으로 트리를 구성합니다. if (!should_run_until_completion && !IsPaused()) { // ... } }
이렇게 만들어진 DOM은 트리형태를 가지고 있어 DOM 트리라고도 불립니다.
css로 style 그리기
이제 css로 스타일을 그려줘야 합니다.
예전에는 html내에 간단한 css 파싱 엔진이 존재했다고하지만, css의 역할이 늘어감에 따라 css 파싱 엔진을 각 브라우저에서 내장하게 되었습니다.
css 역시 html과 마찬가지로 CSSOM(CSS Object Model) 트리를 생성하게 됩니다.

css 파서는 앞서 말씀드렸듯이 블링크 이전에 웹킷의 css 파서 엔진을 크롬에서도 사용하고 있었습니다. 다만 blink를 개발할때 웹킷의 코어한 부분을 가져다 개발하였기 때문에 대부분에 내용은 같습니다.
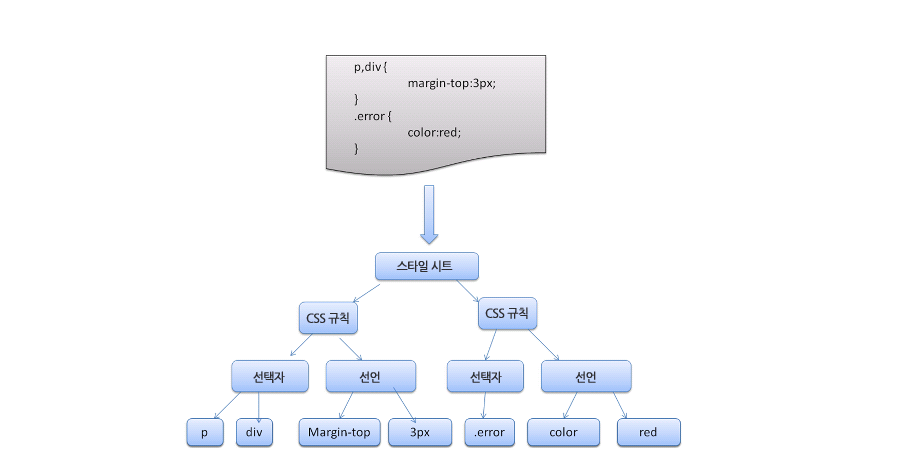
다만 특이하게 css는 html 과 다르게 룰셋이 존재합니다. css 는 선택자와 선언블록으로 나뉘어 각각의 역할을 합니다.
이러한 특징답게 각각 구문마다 토큰화를 하여, 마지막에 cssom 트리를 생성합니다.
-
문자열 css 값을 토큰화
CSSTokenizer tokenizer(string); const auto tokens = tokenizer.TokenizeToEOF(); // 이후 선택자, 색상, 값등을 파싱합니다. -
cssom 트리 생성
// 전체 스타일 시트를 읽어 cssom 트리를 생성합니다. ParseSheetResult CSSParser::ParseSheet( const CSSParserContext* context, StyleSheetContents* style_sheet, const String& text, CSSDeferPropertyParsing defer_property_parsing, bool allow_import_rules) { return CSSParserImpl::ParseStyleSheet( text, context, style_sheet, defer_property_parsing, allow_import_rules); }
완성된 완벽한 페이지
이제 우리는 html과 css를 통해 뼈대를 갖추고, 스타일을 꾸미게 되었습니다.
나머지는 이것을 화면에 보여주기만 하면 끝입니다.
dom 트리와 cssom 트리를 합쳐 우리는 렌더 트리를 만들수 있게 되었습니다.
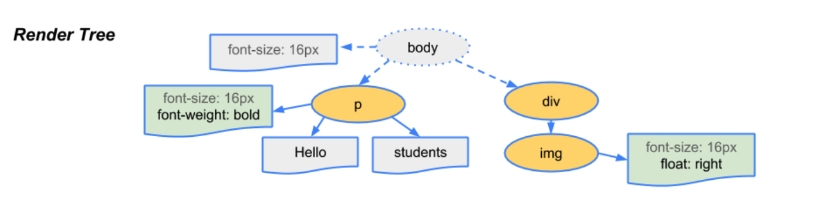
렌더트리는 렌더링에 필요한 노드만 선택하여 페이지를 렌더링하는데 사용합니다.
이후 레이아웃 단계에서는 뷰포트 내에서 각 요소의 정확한 위치와 크기를 정확하게 캡처하는 Box 모델이 출력됩니다
void Document::Initialize() {
// 모든 레이아웃의 기준이 되는 Document 의 레이아웃을 초기화합니다.
layout_view_ = new LayoutView(this);
SetLayoutObject(layout_view_);
// StyleResolver 로 전체 레이아웃의 기준이 될 ViewPort 크기를 계산합니다.
layout_view_->SetStyle(GetStyleResolver().StyleForViewport());
// 이제 Document 에 포함되는 모든 Element 의 레이아웃을 관리할 레이아웃 트리를 구성을 시작합니다.
AttachContext context;
AttachLayoutTree(context);
...
}Element 타입 별로 AttachLayoutTree 함수를 override 해서 Element 특성에 맞게 레이아웃 트리에 추가합니다.
// HTML 의 가장 기본이 되는 HTMLHtmlElement 의 AttachLayoutTree 함수입니다.
void HTMLHtmlElement::AttachLayoutTree(AttachContext& context) {
scoped_refptr<const ComputedStyle> original_style = GetComputedStyle();
if (original_style)
// 레이아웃과 관련한 스타일을 재계산합니다.
SetComputedStyle(LayoutStyleForElement(original_style));
Element::AttachLayoutTree(context);
...
}아래 함수를 보면 스위치문에서 다양한 레이아웃기능이 있다는것을 확인할 수 있습니다.
LayoutObject* LayoutObject::CreateObject(Element* element,
const ComputedStyle& style,
LegacyLayout legacy) {
// 스타일 Display 속성에 맞는 LayoutObject 를 만들어서 반환합니다.
switch (style.Display()) {
case EDisplay::kNone:
case EDisplay::kContents:
return nullptr;
case EDisplay::kInline:
return new LayoutInline(element);
case EDisplay::kBlock:
case EDisplay::kFlowRoot:
case EDisplay::kInlineBlock:
case EDisplay::kListItem:
return LayoutObjectFactory::CreateBlockFlow(*element, style, legacy);
// ...
case EDisplay::kFlex:
case EDisplay::kInlineFlex:
UseCounter::Count(element->GetDocument(), WebFeature::kCSSFlexibleBox);
return LayoutObjectFactory::CreateFlexibleBox(*element, style, legacy);
case EDisplay::kGrid:
case EDisplay::kInlineGrid:
UseCounter::Count(element->GetDocument(), WebFeature::kCSSGridLayout);
return LayoutObjectFactory::CreateGrid(*element, style, legacy);
// ...
}
...
}요약하자면 Document 를 초기화할 때 DOM 트리를 순회하며 레이아웃 관련 스타일 속성을 얻은 뒤, 스타일의 ‘Display’ 속성에 따라 일치하는 LayoutObject 을 생성하여 레이아웃 트리에 추가하는 과정을 반복해서 전체 레이아웃 트리를 완성합니다.
이렇게 완성된 레이아웃 트리는 화면 위에 Element 을 어떻게 배치할지를 결정하는 작업에 활용됩니다.
마지막으로 렌더링 트리의 각 노드를 화면의 실제 픽셀로 변환하게 됩니다. 레이아웃 단계에서 모든 계산이 완료가 되면, 화면에 요소들을 그리게 됩니다. 이 단계를 “페인팅” 또는 “래스터화”라고 합니다.
이미 레이아웃 단계에서 각 노드들이 위치, 크기, 색상 등 스타일이 모두 계산이 되었기 때문에 화면에 실제 픽셀로 변환하게 됩니다.
js코드는 어디서 실행할까?
사실 html과 css말고 js까지 로드되야 완벽한 웹 페이지라고 할수있습니다. 다만 js가 언제 html에 적용되고 그 코드가 브라우저에서 실행되는것은 또 다른 큰 숙제라 다음에 다시 정리해보도록 하겠습니다.
