IP와 브라우저 캐시
2023년 3월 08일
네트워크 통신을 위한 IP
AWS를 이용하면서, 또는 ipconfig를 체크해보면 ip가 10으로 시작하거나 192로 시작하는것을 종종 확인해 볼 수 있습니다. 물론 맥에서조차 해당 ip들을 퍼블릭ip와 프라이빗ip라고 부르고 있습니다.
그래서 저희가 사용하는 퍼블릭ip와 잘 사용하지 않는다고 생각하지만, 실제로는 정말 많이 사용하는 프라이빗ip에 차이를 간단하게 되짚어보려 합니다.
먼저 IP가 뭘까요?
퍼블릭이던 프라이빗이던 우리는 ip를 사용합니다. 딱 봐도 약자인 ip는 무엇을 의미하는것일까요.
IP(Internet Protocol)란 인터넷에 연결되어 있는 모든 장치들(컴퓨터, 서버 장비, 스마트폰 등)을
식별할 수 있도록 각각의 장비에게 부여되는 고유 주소입니다.인터넷은 우리가 아는 인터넷이며, 프로토콜이란 컴퓨터와 컴퓨터간 통신에 있어 서로 같은 방식으로 통신을 할수 있도록 사전에 정의된 규약같은 것입니다.
보통 컴퓨터 네트워크간 전달되는 정보를 패킷1이라고 정의합니다. 위에서 ip가 각 장치를 식별하는 고유 주소라고 말했는데, 이 ip를 패킷정보에 담아 네트워크 통신을 합니다. 그러면 요청받은곳에서 패킷에 있는 ip정보를 찾아 다시 돌려주게 됩니다.
ip주소는 일반적으로 2가지 종류가 있는데 다음과 같습니다.
IPv4
- 일반적인 ip주소를 말하며, 8비트씩 4자리로 되어 있으며 각 자리는 온점으로 구분합니다.
- 0 ~ 2^32 (약 42억 9천)개의 주소를 가질 수 있습니다.
- 현재는 늘어난 인터넷으로 인해 고갈될 위기에 처해있습니다.
IPv6
- IPv4의 주소체계를 128비트 크기로 확장한 차세대 인터넷 프로토콜 주소입니다.
- 16비트씩 8자리로 각 자리는 콜론으로 구분합니다.
- 완전한 상용화가 이루어지지 않았습니다.
물론 ip만으로 통신하는것은 아니고, TCP2나 HTTP3같은 상위의 프로토콜이 합니다.
공인(public)IP
ip는 임의로 우리가 부여하는 것이 아니라 전 세계적으로 ICANN4이라는 모든 ip를 관리하며, 우리나라는 한국인터넷진흥원(KISA)에서 국내 IP 주소들을 관리하고 있습니다.
이것을 ISP5가 부여받고, 우리는 위 회사에 가입을 통해 ip를 제공받아 인터넷을 사용하게 되는 것입니다.
공인 ip는 전세계에서 유일한 ip주소를 가지며, 외부에 공개되어 있기때문에 다른 컴퓨터 네트워크로부터 접근이 가능합니다.
사설(private)IP
사설ip는 쉽게 말하면 기기에서 사용하는 로컬ip입니다.
예를 들면 인터넷 공유기로부터 연결된 부분까지는 공인ip를 할당받지만, 공유기에 연결된 기기들은 각자의 사설 ip를 할당하는데 이 경우 사설ip는 전세계적으로 유일한것이 아닌 하나의 네트워크 안에서만 유일한 주소값을 가집니다.
(같은대역의 ip주소를 가지며 호스트만 다릅니다.)
이 때문에 외부에서 접근 가능한 공인ip와 다르게 사설ip는 네트워크 내부에서만 접근이 가능합니다.
이 덕분에 유한한 ip갯수를 절약하여 사용할 수 있게 됩니다.
ip클래스
사설ip의 경우 내부에서 통신하기 위해서는 같은 대역대여야 하며 호스트가 달라야 합니다.
예를 들면 203.240.100.1에서 203.240.100까지는 네트워크 대역영역이고, 1이 호스트라고 할 수 있습니다. 그렇다면 우리는 어떻게 저 영역을 구분할 수 있을까요?
그 이유는 저 ip는 c클래스이며, 사설 ip는 클래스 개념이 있기 때문입니다.
사설ip클래스는 총 5종류가 있으나, 실질적으로는 3종류만 사용한다고 하며 각 클래스에 대한 설명은 다음과 같습니다.
- A클래스 : 처음 8bit(1byte)가 Network ID이며, 나머지 24bit(3byte)가 Host ID로 사용됩니다. 비트가 0으로 시작하기에 네트워크 할당은 0~127입니다 . 즉, 128 곳에 가능하며, 최대 호스트 수는 16,777,214개입니다.
- B클래스 : 처음 16bit(2byte)가 Network ID이며, 나머지 16bit(2byte)가 Host ID로 사용됩니다. 비트가 10으로 시작하기에 네트워크 할당은 16,384 곳에 가능하며, 최대 호스트 수는 65,534개입니다.
- C클래스 : 처음 24bit(3byte)가 Network ID이며, 나머지 8bit(1byte)가 Host ID로 사용됩니다. 비트가 110으로 시작하기에 네트워크 할당은 2,097,152 곳에 가능하며, 최대 호스트 수는 254개입니다.
각각의 Class를 제일 첫 번째 옥텟으로 구분하실 수 있습니다.
(네트워크 범위가 커질수록 호스트 주소 범위는 작아집니다.)
NAT
사설ip의 경우 외부접근이 힘들다고 했는데, 또 아예 불가능한것은 아닙니다. 외부와 통신할 수 있는 방법은 있습니다.
그런데, 생각해보면 ip는 전세계적으로 유일한 주소입니다. 하지만 사설ip는 하나의 네트워크안에서만 유일한 주소입니다. 그렇다면 당연히 다른 네트워크의 사설ip와 중복되는 문제가 발생할 수 있습니다.
이런 경우 어떻게 원하는 방향으로 패킷을 주고받을수 있을까요?
여기서 바로 NAT(Network Adress Translation)이란 개념이 등장합니다.
거창하게 보이지만 직역해보면 네트워크 주소 변환기로, 사설 ip가 연결되어 있는 공유기(라우터)에서 공인ip로 변환하여 외부와 통신하는것을 의미합니다.
자 그러면 통신후에는?
자 우리는 IP를 이용하여 네트워크 통신에 성공하여 패킷 내에 있는 정보를 받았습니다. 이 경우 다양한 정보가 있을겁니다. 하지만 용량이 작은 json부터 용량이 큰 이미지나 영상같은 데이터도 있을것입니다.
그렇다면 웹에서 용령이 큰 데이터를 항상 요청해서 받아야 하는걸까요?
받은 후에 실수로 새로고침이라도 한다면, 다시 이미지를 불러오는데 불필요한 리소스를 들여야 하는걸까요?
웹 캐시
이러한 데이터를 빠르게 재 호출하기 위해 바뀌지 않은 데이터의 사본을 저장해 다시 불러와 사용하는것을 캐시라고 합니다. 그리고 다양한곳에서 캐시를 이용해 중복된 요청을 하지 않고 있습니다.
웹에서 다루는 중요한 캐싱방법은 3가지가 있습니다.
- Browser Caches
- Proxy Caches
- Gateway Caches (REVERSE OR SURROGATE PROXY)
그 중 가장 쉽고 빈번하게 사용할 수 있는 브라우저 캐시에 대해 알아보겠습니다.
브라우저 캐시
사용자는 인터넷 홈페이지에서 한번의 클릭으로 정말 많은 요청을 합니다. 그럴때마다 모든 요청된 데이터를 다시 불러온다면 분명 비효율적일 것입니다.
그래서 브라우저에서는 브라우저 캐시를 이용하여 효율적인 요청을 하고 있습니다.
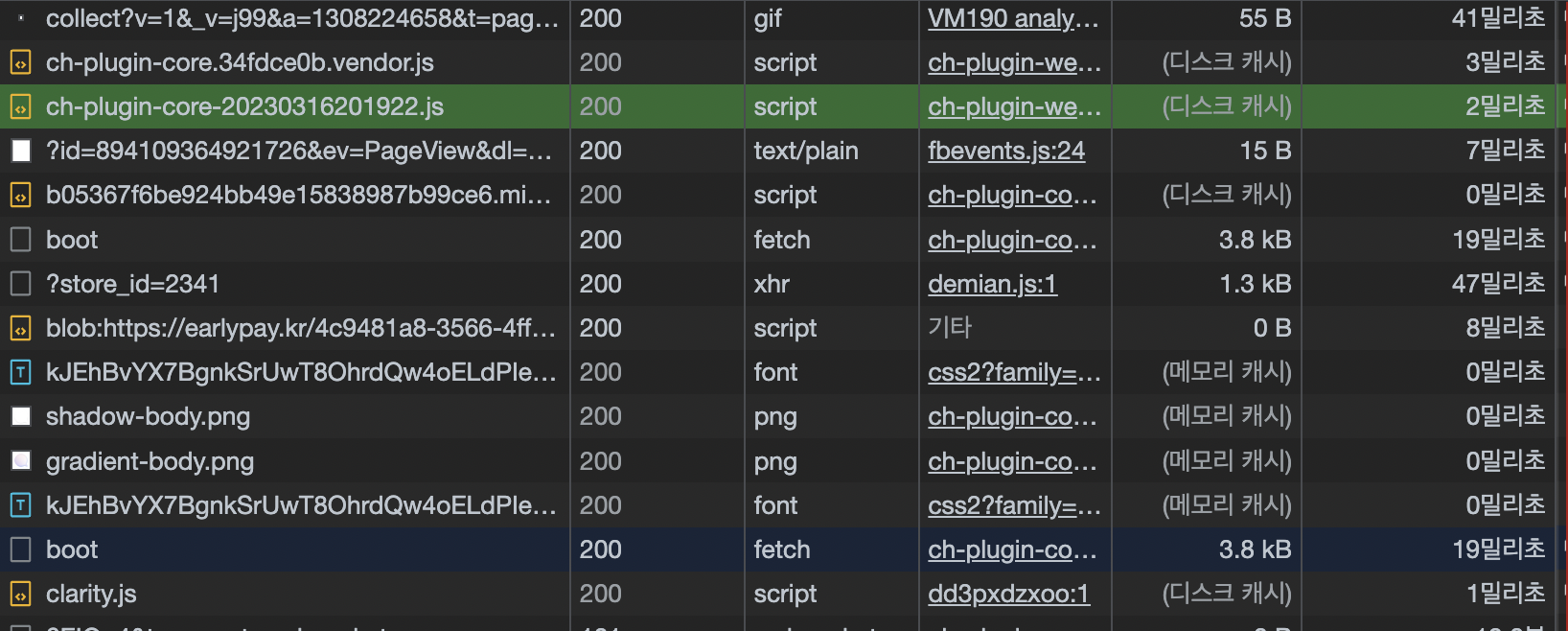
네트워크 탭을 보면 이런 화면을 보실 수 있을겁니다. 디스크캐시와 메모리캐시를 확인해 볼 수 있습니다. 그리고 캐싱된 파일은 다른 요청에 비해 현저하게 낮은 로딩시간을 확인할수 있습니다.
특히 메모리 캐시의 경우 0에 가까운 시간을 보여주는데, 이렇듯 브라우저 캐시는 저장공간에 따라 디스크 캐시와 메모리 캐시로 나누어 지게됩니다.
디스크 캐시
- 디스크 캐시는 디스크에 저장되는 캐시입니다.
- 메모리 캐시보다는 성능이 느리지만, 브라우저 종료나 새로고침에도 캐시가 남아있습니다.
- 일반적으로 메모리캐시보다 큰 용량을 가지고 있습니다.
메모리 캐시
- 디스크 캐시는 RAM에 저장되는 캐시입니다.
- 메모리 캐시보다는 성능은 빠르지만 각 탭별로 독립적이며, 새로고침이나 종료시 데이터가 휘발됩니다.
- 디스크캐시보다는 적은 용량을 가지고 있습니다.
그렇기 때문에 일반적으로 캐시가 없는 웹사이트를 최초로 불러 올 경우 모두 정상적으로 불러오며, 이후 정적파일(html,css,js,img …)등 을 디스크 캐시와 메모리 캐시로 구분하여 저장합니다.
이때 브라우저 내부 알고리즘에 의해 저장되는 위치가 결정되는데, http header에 max-age영향을 받는다고도 합니다.
이 상태에서 브라우저를 새로고침하거나, 라우팅을 할 경우 기존 데이터가 캐시된것을 확인 할 수 있습니다.
다만 메모리 캐시의 경우 브라우저를 종료하면(크롬기준) 메모리캐시는 휘발되어 캐시가 초기화됩니다.
브라우저 캐시 동작 원리
그렇다면 요청에 대해 브라우저는 어떤 동작으로 캐시처리를 하는지 간단하게 알아보겠습니다.
- 브라우저는 서버에 요청을 합니다.
- 서버는 요청받은 결과를 브라우저에게 전달합니다.
- 만약 응답 헤더에 Last-Modified, Etag, Expires, max-age 항목이 존재 한다면 복사본을 생성하고 그 값을 저장합니다.
- 재요청을 할 경우 Cache-Control:max-age 값을 보고, max-age기간이 지나지 않았다면 재요청을 하지않고 캐시된 데이터를 사용합니다.
- max-age기간이 지났다면 요청시 Last-Modified, Etag, Expires값들을 If-None-Match header에 담아 보냅니다.
- 서버는 해당 값들을 비교하여 수정되지 않았다고 판단된다면 304 Not Modified를 리턴하며 해당 데이터에 갱신시간을 120초 늘려줍니다.
- 만약 파일이 수정되었다면, 새로운 Last-Modified, Etag, Expires, max-age 값들과 함께 요청된 데이터를 내려줍니다.
브라우저 캐시를 잘 쓴다면..
요즘 리액트쿼리를 많이 사용하는데, 이런 요청도 사실 캐싱될 수 있습니다. 물론 유동적인 응답값에 대한 요청은 쉽게 캐시를 할 수는 없을것입니다. 다만 이런 브라우저 캐시를 잘 이용한다면 더 적은 요청으로 서버와 통신할수 있지 않을까 싶습니다.
